
如何使用 BigQuery 和 Langchain 构建数据分析助手

由于企业每天都会生成大量数据,因此从所有这些信息中提取有用的见解可能非常困难,尤其是在数据集复杂且数据量巨大的情况下。但借助生成式人工智能,我们可以简化和自动化数据分析,使其高效且易于访问。在本文中,我将向您展示如何使用 Google Langchain、OpenAI、BigQuery和数据丢失防护(DLP)设置和使用人工智能数据分析助手。
用例:使用 BigQuery 自动进行数据分析
解决方案设计
该解决方案涉及使用 Langchain 和 OpenAI 设置 Streamlit 应用,该应用与 BigQuery 数据集交互以自动进行数据分析。该代理将使用自定义工具执行特定任务,例如屏蔽 PII 客户属性和可视化数据。此外,代理将配置为保留聊天记录,确保响应符合上下文。

让我们考虑一个场景,其中我们有一个包含下表的 BigQuery 数据集:
- 客户表:包含客户数据。
- 联系表:包含客户联系方式。
- 客户地址表:将客户与地址联系起来。
- 地址表:包含地址信息。
- 作业统计表:记录截断并将数据加载到客户资料表中的 ETL 批处理作业摘要

设置 Langchain
什么是 Langchain?
LangChain 为 AI 开发人员提供将语言模型与外部数据源连接起来的工具。它是开源的,并得到活跃社区的支持。组织可以免费使用 LangChain,并获得其他精通该框架的开发人员的支持。
要使用 Langchain 进行数据分析,我们首先需要安装 Langchain 和 OpenAI 库。这可以通过下载必要的库然后将其导入到您的项目中来完成。
安装 Langchain:
pip install langchain matplotlib pandas streamlit
pip install -qU langchain-openai langchain-community定义 Langchain 模型并设置 Bigquery 连接:
import os
import re
import streamlit as st
from google.cloud import dlp_v2
from google.cloud.dlp_v2 import types
from langchain.agents import create_sql_agent
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.messages import AIMessage
from langchain_core.prompts import (
SystemMessagePromptTemplate,
PromptTemplate,
FewShotPromptTemplate,
)
from langchain_core.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
from langchain.memory import ConversationBufferMemory
from langchain_experimental.utilities import PythonREPL
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.sql_database import SQLDatabase
from langchain.tools import Tool
service_account_file = f"{os.getcwd()}/service-account-key.json"
os.environ["OPENAI_API_KEY"] = (
"xxxxxx"
)
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = service_account_file
model = ChatOpenAI(model="gpt-4o", temperature=0)
project = "lively-metrics-295911"
dataset = "customer_profiles"
sqlalchemy_url = (
f"bigquery://{project}/{dataset}?credentials_path={service_account_file}"
)
db = SQLDatabase.from_uri(sqlalchemy_url)设置自定义工具
为了增强我们代理的能力,我们可以为特定任务设置自定义工具,例如屏蔽 PII 数据和可视化数据。
- 使用 Google Cloud DLP 掩盖 PII数据隐私至关重要。为了保护输出中的 PII,我们可以利用 Google Cloud 数据丢失防护 (DLP)。我们将构建一个自定义工具,调用 DLP API 来屏蔽响应中存在的任何 PII 数据。
def mask_pii_data(text):
dlp = dlp_v2.DlpServiceClient()
project_id = project
parent = f"projects/{project_id}"
info_types = [
{"name": "EMAIL_ADDRESS"},
{"name": "PHONE_NUMBER"},
{"name": "DATE_OF_BIRTH"},
{"name": "LAST_NAME"},
{"name": "STREET_ADDRESS"},
{"name": "LOCATION"},
]
deidentify_config = types.DeidentifyConfig(
info_type_transformations=types.InfoTypeTransformations(
transformations=[
types.InfoTypeTransformations.InfoTypeTransformation(
primitive_transformation=types.PrimitiveTransformation(
character_mask_config=types.CharacterMaskConfig(
masking_character="*", number_to_mask=0, reverse_order=False
)
)
)
]
)
)
item = {"value": text}
inspect_config = {"info_types": info_types}
request = {
"parent": parent,
"inspect_config": inspect_config,
"deidentify_config": deidentify_config,
"item": item,
}
response = dlp.deidentify_content(request=request)
return response.item.value- Python REPL接下来,为了使 LLM 能够使用 Python 执行数据可视化,我们将利用 Python REPL 并为我们的代理定义一个自定义工具。
python_repl = PythonREPL()现在,让我们创建代理工具,其中 mask_pii_data 包括 python_repl:
def sql_agent_tools():
tools = [
Tool.from_function(
func=mask_pii_data,
name="mask_pii_data",
description="Masks PII data in the input text using Google Cloud DLP.",
),
Tool(
name="python_repl",
description=f"A Python shell. Use this to execute python commands. \
Input should be a valid python command. \
If you want to see the output of a value, \
you should print it out with `print(...)`.",
func=python_repl.run,
),
]
return tools使用少量样本
为模型提供少量示例有助于指导其响应并提高性能。
定义示例 SQL 查询,
# Example Queries
sql_examples = [
{
"input": "Count of Customers by Source System",
"query": f"""
SELECT
source_system_name,
COUNT(*) AS customer_count
FROM
`{project}.{dataset}.customer`
GROUP BY
source_system_name
ORDER BY
customer_count DESC;
""",
},
{
"input": "Average Age of Customers by Gender",
"query": f"""
SELECT
gender,
AVG(EXTRACT(YEAR FROM CURRENT_DATE()) - EXTRACT(YEAR FROM dob)) AS average_age
FROM
`{project}.{dataset}.customer`
GROUP BY
gender;
""",
},
...接下来,定义前缀和后缀,然后 few_shot_prompt 直接传递到 from_messages 工厂方法中。
注意:SUFFIX 中有一个 {chat_history} 变量,当我们创建代理和添加内存时,我将在下一步中解释它。
PREFIX = """
You are a SQL expert. You have access to a BigQuery database.
Identify which tables can be used to answer the user's question and write and execute a SQL query accordingly.
Given an input question, create a syntactically correct SQL query to run against the dataset customer_profiles, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table; only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the information returned by these tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If the question does not seem related to the database, just return "I don't know" as the answer.
If the user asks for a visualization of the results, use the python_agent tool to create and display the visualization.
After obtaining the results, you must use the mask_pii_data tool to mask the results before providing the final answer.
"""
SUFFIX = """Begin!
{chat_history}
Question: {input}
Thought: I should look at the tables in the database to see what I can query. Then I should query the schema of the most relevant tables.
{agent_scratchpad}"""
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=PromptTemplate.from_template(
"User input: {input}\nSQL query: {query}"
),
prefix=PREFIX,
suffix="",
input_variables=["input", "top_k"],
example_separator="\n\n",
)
messages = [
SystemMessagePromptTemplate(prompt=few_shot_prompt),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{input}"),
AIMessage(content=SUFFIX),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
prompt = ChatPromptTemplate.from_messages(messages)变量解释
- 输入:用户的输入或查询。
- agent_scratchpad:中间步骤或想法的临时存储区域。
- chat_history:跟踪以前的互动以维护背景。
- handle_parsing_errors:确保代理可以正常处理解析错误并从中恢复。
- memory:用于存储和检索聊天历史的模块。
现在是最后一步了。让我们构建应用程序吧!
使用 Streamlit 构建 LLM 应用程序
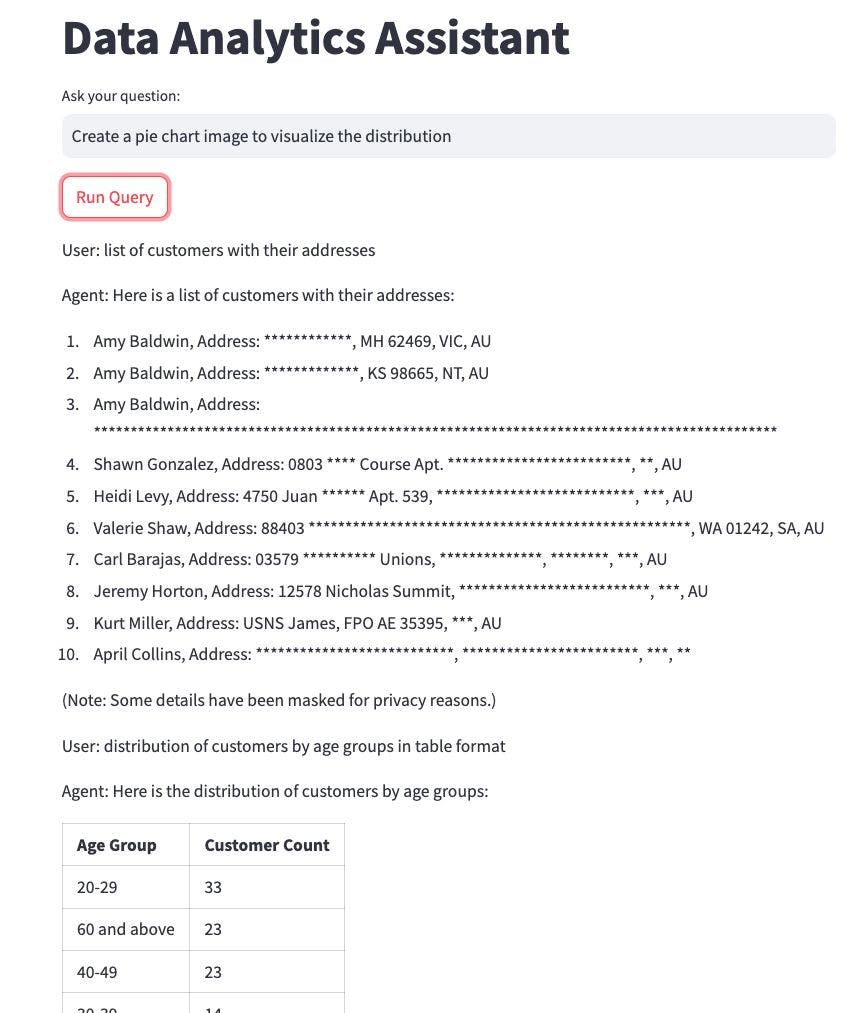
为了创建一个交互式界面来测试我们刚刚构建的 Langchain 代理,我们可以使用 Streamlit。
st.title("Data Analysis Assistant")
if "history" not in st.session_state:
st.session_state.history = []
user_input = st.text_input("Ask your question:")
if st.button("Run Query"):
if user_input:
with st.spinner("Processing..."):
st.session_state.history.append(f"User: {user_input}")
response = agent_executor.run(input=user_input)
if "sandbox:" in response:
response = response.replace(f"sandbox:", "")
match = re.search(r"\((.+\.png)\)", response)
if match:
image_file_path = match.group(1)
if os.path.isfile(image_file_path):
st.session_state.history.append({"image": image_file_path})
else:
st.error("The specified image file does not exist.")
else:
st.session_state.history.append(f"Agent: {response}")
st.experimental_rerun()
else:
st.error("Please enter a question.")
for message in st.session_state.history:
if isinstance(message, str):
st.write(message)
elif isinstance(message, dict) and "image" in message:
st.image(message["image"])我们已经设置好了一切。让我们运行 Streamlit 应用
streamlit run app.py

结论
通过利用 Langchain 和 OpenAI,我们可以自动执行复杂的数据分析任务,从而更轻松地从大型数据集中获取见解。这种方法不仅节省时间,而且可以确保准确一致的分析。无论您处理的是客户资料、联系信息还是工作统计数据,人工智能驱动的数据分析助手都可以大大提高您的数据处理能力。有关完整源代码,请访问 GitHub 存储库。



{kind=link}
{kind=link}
{kind=link}